视频流切片服务设计
这里记录下终端录制视频流切片并上传的流程设计与优化过程: 1. ffmpeg -i rtmp://xxxxx:1935/yyyy/zzzz/vision -c:v h264 -flags +cgop -g 0 -hls_flags program_date_time -hls_list_size 0 -hls_time 10 /app/data/record.m3u8 -y
2. ffmpeg -hide_banner -f concat -safe 0 -i files.txt -ss 00:00:18 -t 00:00:40 -c copy -hls_list_size 0 ./output.m3u8
这里是实现最原始切片方案的核心逻辑,下面会解释流程,然后列出自己的优化过程。
最简原型
录制逻辑
ffmpeg -i rtmp://xxxxx:1935/yyyy/zzzz/vision -c:v h264 -flags +cgop -g 0 -hls_flags program_date_time -hls_list_size 0 -hls_time 10 /app/data/record.m3u8 -y
这里从rtmp://xxxxx:1935/yyyy/zzzz/vision 视频流获取 然后添加:
-hls_flags program_date_time使用#EXT-X-PROGRAM-DATE-TIME时间扩展 ,在m3u8 文件中记录每个切片的开始时间,重要-hls_list_size 0配置 m3u8 为记录所有ts 文件-c:v h264确保格式为h264
切片逻辑
切片最重要的是解析m3u8 文件,判断请求的时间是否在文件记录的范围内,是的话将其加入到concat 文件中,然后更新ss 也就是切片开始时间,最后执行下述切片指令;
ffmpeg -hide_banner -f concat -safe 0 -i files.txt -ss 00:00:18 -t 00:00:40 -c copy -hls_list_size 0 ./output.m3u8
-i files.txt输入concat 文件,这里是切片的核心逻辑-ss 00:00:18 -t 00:00:40切片起始时间和持续时间-c copy不做编码,直接复制-hls_list_size 0配置 m3u8 为记录所有ts 文件
上传逻辑
- 使用tar 对目标目录下所有非tar 后缀文件进行归档;
- 创建分片上传请求,拿到上传id
- 使用上传id 去分片上传大文件,设置有效时间
- 确认上传成功后主动清理 目标目录
优化
上述实现流程中存在以下问题:
- 切片太慢,多个视角有放大效应
- 录制太占用资源,观察到最极端场景 113% cpu 占用
top
录制逻辑优化
首先在测试需要录制的视频流格式,获得以下信息:
Metadata:
|RtmpSampleAccess: true
fileSize : 0
title : Streamed by ZLMediaKit(git hash:f3026f5/2025-01-12T10:16:45+08:00,branch:master,build time:2025-01-12T02:24:04)
Duration: 00:00:00.00, start: 2196.413000, bitrate: N/A
Stream #0:0: Data: none
Stream #0:1: Video: h264 (Constrained Baseline), yuv420p(progressive), 768x432, 10 fps, 10 tbr, 1k tbn
Stream #0:2: Audio: aac (LC), 8000 Hz, mono, fltp
可以看到视频编码格式是 H264 ,和切片的编码相同,使用 -c copy 直接复制即可。
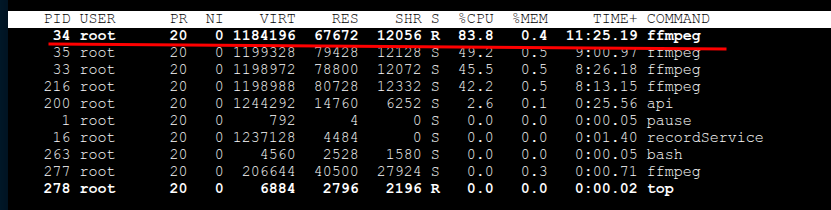
上下分别是修改前后的资源占用情况 TOP
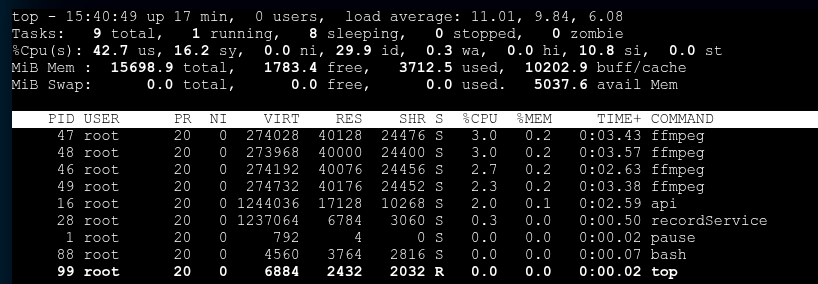
最低也节省了40%*4 的cpu 资源
这里还可以利用hls_warp 来实现滚动录制,但是得需要手动拷贝到目标目录然后重建m3u8,长期录制需要去做这个,另外这里的优化为后面的切片逻辑让出了余裕。
切片逻辑优化
切片主要是有以下几个问题:
- 会随着 -ss 开始切片的值,导致切片耗时增长
- 多个视角使用串行一次完成录制
针对问题1,可以检索到ffmpeg 命令行文档中记录
-ss position (input/output)
When used as an input option (before -i), seeks in this input file to position. Note that in most formats it is not possible to seek exactly, so ffmpeg will seek to the closest seek point before position. 当使用-ss时,会先seek 到指定位置,(如果可能的话),然后开始解码
应对策略,在需要切片的视频只命中了一个M3U8文件,去掉合并逻辑,直接从m3u8 切片,使用-ss 优化 切片耗时:
在,更正优化策略,通过跟踪观察对HLS类型的录制,直接使用-ss 无法实现预先中的seek 定位,需要手动从原始M3U8 中切出子播放列表,是的可以用 -ss 0 来从子切片的位置开头的位置处直接提取,优化效果1分钟的切片可以在秒级完成,可以满足合规要求-i 之前使用 -ss 可以利用seek 操作,快速定位,提升切片效率,测试后观察切片时间平均减半
| |
针对问题2,决定使用多协程并发处理:
- 使用视角+uuid 方式分离
-i参数给的合并输入文件命名,分离多协程之间的干扰; - 利用
sync.WaitGroup和context.Context来协同父子进程,在子进程完成多个视角切片后,解除阻塞,继续后面的流程tar-> 分片上传;
结果
ffmpeg -i rtmp://xxxxx:1935/yyyy/zzzz/vision -c:v copy -flags +cgop -g 0 -hls_flags program_date_time -hls_list_size 0 -hls_time 10 /app/data/record.m3u8 -y大幅减少cpu 资源消耗ffmpeg -y -hide_banner -ss 00:00:18 -t 00:00:40 -i xxx.m3u8 -c copy -hls_list_size 0 ./output.m3u8seek 快速定位,避免读取开头的切片,并发协同